[그림1] 취학 아동 사례
안녕하세요. "생각의웹"입니다.
근 몇 년간 핫 이슈였던 빅데이터에 대해 환상이 사그라지는 분위기지만 데이터 기반 접근법(data approach)는 모든 분야에 있어 원칙으로 자리잡고 있습니다. 2015년 가트너의 경우, 매년 발표하는 Hype Cycle for Emerging Tech. 에서 빅 데이터를 제외했는데 그 이유로 더이상 빅 데이터가 특정 기술이 아닌 모든 산업의 기반 기술로써 편재하게 되었기 때문이라고 언급한 바 있습니다.

[그림 2] Gatner Hype Cycle 2015 - 더이상 Big data를 찾아 볼 수 없다
빅데이터와 더불어 미래를 이끌 것으로 예견되는 기술들 역시 막연한 환상에서 벗어나 가치에 대해 재조명되어가는 형국입니다. 그림2는 사물인터넷(IoT)와 기계학습(ML) 그리고 웨어러블 등이 죽음의 골짜기(death valley)를 향하고 있음을 보여주는데 이 모든 기술들이 근 몇 년동안 세상을 바꿀 신기술들로 빠르게 성장(hype)했음을 주목할 필요가 있습니다.
앞서 언급한 빅데이터, 사물인터넷, 기계학습, 웨어러블 기술은 상호 밀접한 관계를 가지고 있습니다. 예를 들어, 웨어러블 기기가 생체신호 및 위치 정보를 다수의 사람들에게서 수집하여 빅데이터 화하고 기계학습을 이용해 데이터마이닝(data mining)한 후 찾은 인사이트를 기반으로 가설(hypothesis)을 만들고 실험(experiments)을 통해 증명하게 됩니다. 이때, 사물인터넷을 이용해 다양한 기기들과 상호작용하여 실험 결과를 도출하는 과정이라고 할 수 있겠습니다. 이 모든 과정의 본질은 데이터에서 가치를 추출하는 과정 즉, 데이터 분석입니다. 이번 포스팅에서는 간략하게 등하교 알림 데이터로 실 사례로 이 과정을 예시해 보도록 하겠습니다.

[그림3] SMS 메시지와 SMS dump 도구 (SMS to Text)
0. 준비물
- 아이의 등하교 알림 메세지 (by JT통신 i알리미 서비스)
- SMS to Text (from google Play 스토어)
- MS Excel
1. 배경
올 해 아이가 초등학교에 입학하게 되어 명실상부 학부모가 되었습니다. 대부분 초등학교는 집에서 멀지 않은 곳으로 배정받게 되는데 제가 살고 있는 곳에서 초등학교 가는 길이 걸어서 통학하기에는 위험요소가 많습니다. 따라서, 학원 차량 편을 통해 통학하고 있는데 혹시 차량 이동 간에 있을 수 있는 사고에 신경이 쓰입니다.
이런 이유에서인지 해당 학교에서는 비콘 기반의 등하교 확인 서비스를 시작했는데 그림 3과 같이 아이의 등하교 시 등록된 부모의 연락처에 SMS를 보내주는 서비스입니다.
2. 전처리
SMS를 가공하기 위해서 SMS log를 텍스트 파일로 저장해주는 도구를 다운로드 받습니다. (그림 3은 SMS to Text 라는 도구를 보여줍니다.) 이 도구를 통해 관련된 메시지를 csv파일로 저장하고 이 파일을 컴퓨터로 가져옵니다.
csv파일을 엑셀로 열면 한글이 깨져 보입니다. 따라서 텍스트 에디터로 열어 한글을 제거하고 중복되는 문구를 의미에 맞도록 바꿉니다.
Date,Time,Type,Number,Name,Who,Date2,At,Where,Count 2016-04-27,13:21:27,in,16444265,16444265,joyan,4/27,13:21,front gate,-1 2016-04-28,08:44:54,in,16444265,16444265,joyan,4/28,08:44,front gate,1 2016-04-28,13:56:45,in,16444265,16444265,joyan,4/28,13:56,front gate,-1

[그림4] 전처리 후 데이터
그림4는 메세지 내용을 정리해서 누가 언제 어디로 출입했는지로 정리했음을 보여줍니다.
3. Tidy data table로 변경
전처리를 완료된 데이터셋을 excel로 불러들인 후, 분석에 불필요한 정보를 제거 합니다. 앞서 그림4에서 Type, Number, Name은 모두 동일한 값들이라 제거합니다.
또한 등교를 학교에 학생이 증가한다는 의미로 +1를, 하교를 -1로 바꾸어 Count 항목으로 명시합니다.
4. Feature engineering
Feature engineering이란 기계학습 알고리즘에 활용하기 위한 features를 생성하는 것으로 이때 domain knowledge를 활용[Wikipedia]합니다. 여기에서 추가 설계한 feature는 다음과 같습니다.
- 요일: 해당 날짜의 요일을 1~7로 표현. (일: 1, 월: 2, 화: 3, 수: 4, 목: 5, 금: 6, 토: 7)
- 출입시간과 SMS 수신 시간의 차: SMS는 지연이나 누락될 수 있는 서비스라서 지연 시간을 계산

[그림5] Feature Engineering 결과
5. 탐색적 데이터 분석 (Exploratory Data Analysis, EDA)
데이터의 일부를 발췌하여 보거나 통계적 특성을 살피면서 데이터의 특성을 파악하는 작업입니다. 시각화(visualization)을 활용해서 시각적 특성을 찾으면 좋은 인사이트를 발굴할 수 있습니다. 먼저, 통계적 특성을 확인하기 위해 사용하는 시각화 기법으로 상자수염그림(boxplot), 산점도(scatterplot)이 있어서 이것을 그려보기로 했습니다.

[그림6] At과 Count로 그린 상자 수염 그림
그림6은 등하교시간과 등하교 형태로 그린 상자 수염 그림[위키] 입니다. 그림에서 보듯 하교(-1)는 평균 (mean) 시간은 오후 1시 29분이고 1사분위와 3사분위 값이 각각 오후 12시 46분에서 1시 58분임을 보여줍니다. 반대로 등교시간은 상대적으로 일정한데 평균 값은 8시 45분입니다. 약 15분 전에 정문을 통과한다고 볼 수 있겠네요. 0 값으로 표시된 경우는 정문에 설치된 비콘에 등교 이후 관찰되었을 경우 메시지를 전달하는 경우로 보이는데 유용성을 이해하기 힘듭니다. 일단 하교 시간의 변화(variance)가 커서 이를 요일 별로 분석해 보도록 하겠습니다.

[그림7] At 과 Count로 그린 산점도
그림7은 요일별로 관찰된 출입시간을 점으로 표시한 것입니다. 앞서 그림6에서처럼 등교 시간은 일정하게 모이는 반면, 하교 시간은 월/수 (2/4)와 수/목(3/5), 금(6)이 사뭇 다르게 보입니다. 이는 아이의 시간표에 따라 귀가 시간이 변하기 때문에 나타나는 당연한 결과라고 볼 수 있습니다. 다만, 수요일 1시 21분에 하교한 사례나 금요일 오후 2시 39분 사례처럼 특이점이 있으니 이유를 살펴 보아야 할 것 같습니다.
6. Findings
앞서 EDA에서 보여주듯 관찰을 통해 일상의 통학 시간을 확인할 수 있습니다. 이는 기계학습을 통해 정상적으로 통학했음을 확인할 수 있는 모델을 만들 수 있다는 의미로 해석할 수 있습니다. 지금은 데이터가 매우 적은 관계로 일반화할 수 없지만 같은 반이나 같은 학년의 데이터를 활용할 수 있으면 가능할 것이라고 기대합니다.
일상적인 등하교 시간에 대한 모델을 학습할 수 있게 된다면 이를 통해 비정상 상황을 예측할 수 있습니다. 예를 들면 등교 시간이 평소보다 많이 지연되었을 경우 확인 요청 문자를 발송한다거나, 하교 시간이 평소보다 늦어질 경우, 교사에게 확인 요청 메시지를 발송해서 학부모들의 우려를 먼저 대처할 수 있습니다.
비콘을 이용한 통학 안전 관련 서비스의 핵심은 특이점 찾기(outlier detection) 입니다. 좀 더 쉽게 말하면, 등교 시간이 넘었음에도 관찰이 되지 않거나, 하교 시간이 매우 지연되는 사례 혹은 관찰이 되지 않는 경우를 들 수 있습니다. 이때 공휴일 여부/비콘 기기 정상 동작 여부 등의 외부 정보가 매우 중요한데 잘못된 알림이 시스템의 신뢰도에 치명적인 손상을 가져오기 때문입니다.
7. Future Works
이 문자 메세지는 정상 상황에서만 알림을 주도록 설계되어 있습니다. 하지만 정작 중요한 정보는 비정상 상황에서의 알림입니다. 그럼에도 불구하고 이상 알림(False Alarm)에 대한 부담감 때문에 이런 서비스를 제공하기 쉽지 않다는 게 현실입니다.
이에 대해 활용자가 위험을 부담하는 DIY 서비스를 만들 수 있도록 하면 어떨까요? SMS 정보를 입력으로 학습하고 알람에 대한 평가를 반영해 성능을 개선해 가는 기계학습 시스템을 생각해 보게 됩니다.
'Web of Intelligence > Small_Data' 카테고리의 다른 글
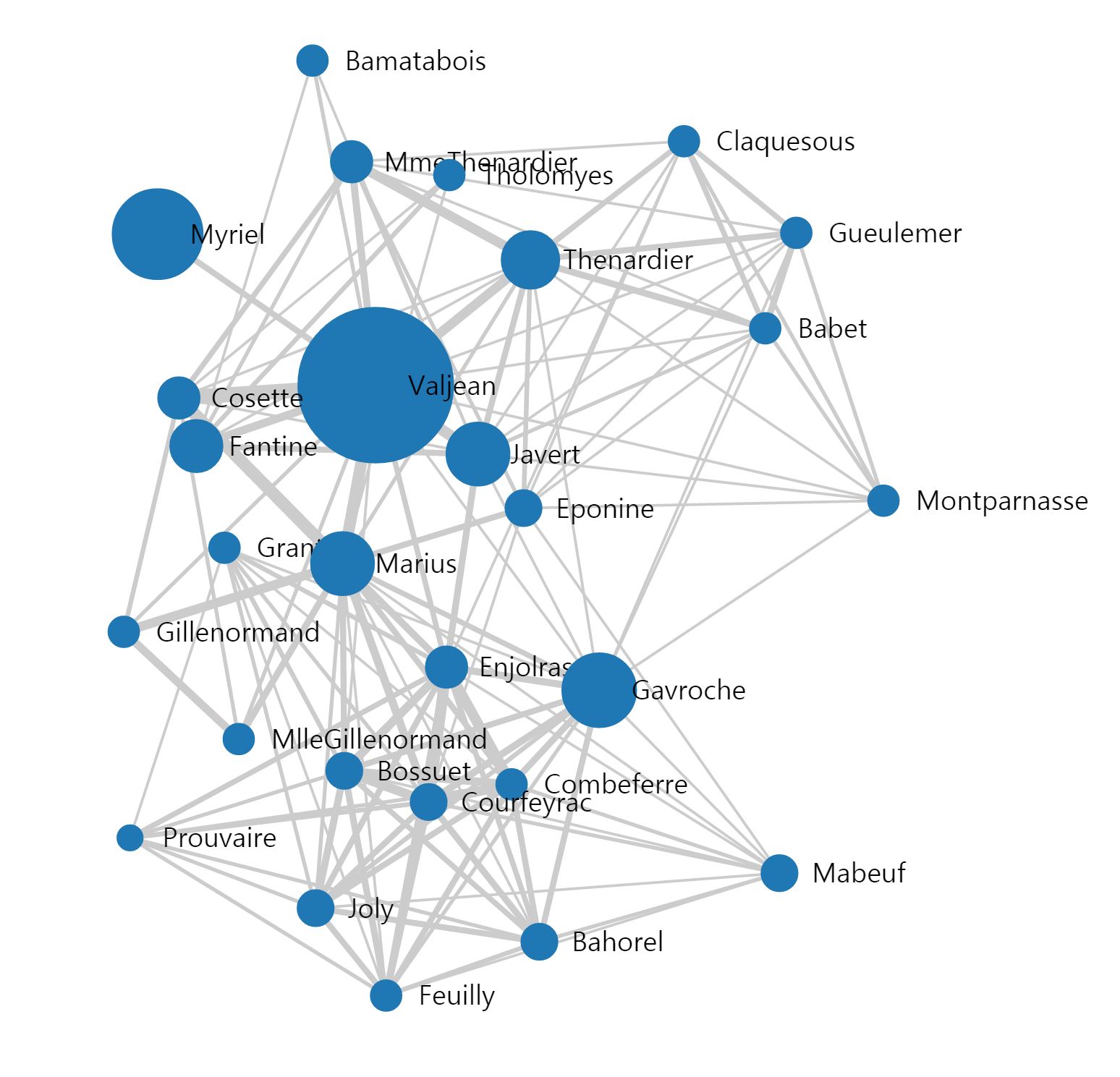
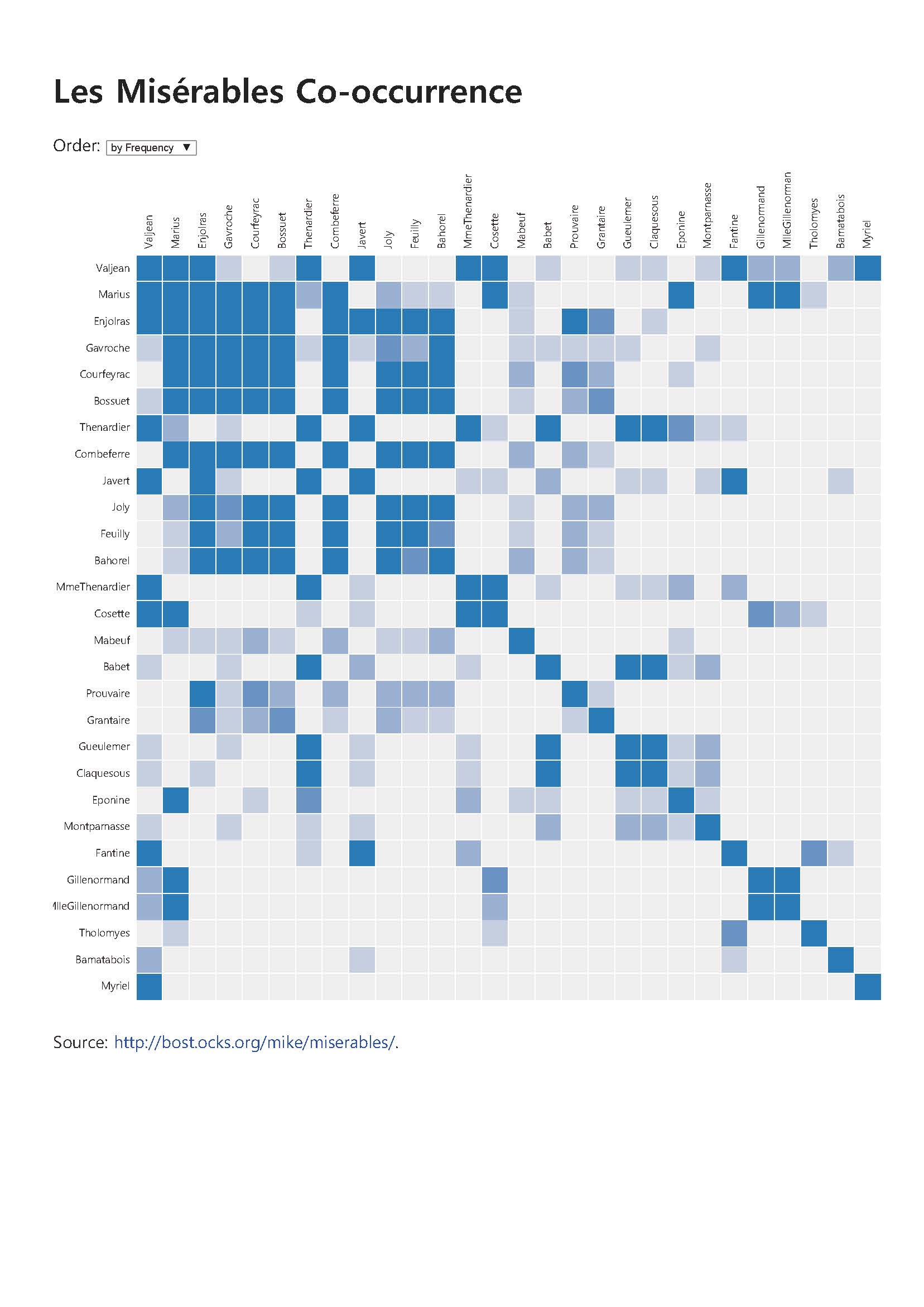
| A Butterfly of the Dawn: "레 미제라블 등장 인물 관계 분석을 통한 임계 사회에서의 나비 효과 통찰' (0) | 2015.04.17 |
|---|---|
| Facebook feed로 word cloud 만들기 (0) | 2015.03.31 |
| Python 2.7 + NLTK를 windows 8 설치 시 한글 경로 문제 해결 방법 (0) | 2015.03.31 |
| Tweet 분석해 word cloud 만들기 (4) | 2015.03.26 |
| Python 2.7 + NLTK windows 8.1 (64bit)에 설치하기 (2) | 2015.03.24 |